
windows 应用程序分类
控制台应用程序,DOS程序,本身没有窗口,通过Windows DOS窗口执行。
窗口程序,拥有自己的窗口,可以与用户交互。
库程序,存放代码、数据的程序,执行文件可以从中取出代码执行和获取数据。
- 静态库程序:扩展名LIB,在编译链接程序时,将代码放入到执行文件中。
- 动态库程序:扩展名DLL,在执行文件执行时从中获取代码。
关于库程序,Windows和Linux平台是一样的,只不过实现的细节和手法上不一样。静态库里面的代码会直接嵌入到开发人员写的代码中。而动态库里面的代码并不会直接嵌入到开发人员写的代码中,而是提供一个地址进行调用。Linux中的静态库文件是以.a 为后缀,动态库文件是以.so为后缀。
静态库程序没有入口函数,无法执行,意味着无法进入内存。静态库的源文件包括实现函数和变量的源代码,以及相关的头文件。源文件中的具体实现通过编译器生成目标文件(.o或.obj),然后这些目标文件打包成静态库文件(.a或.lib)。
动态库程序有一个 DllMain() 函数,就是动态库程序的主函数,可以执行,即可以进入内存。动态库程序可以运行,它不能独立的运行,它必须依附于其他程序运行。谁调用动态库里面的东西,就依附于谁运行。
入口函数对比:
- 入口函数:
- 控制台应用程序 -
mian() - 窗口应用程序 -
WinMain() - 动态库程序 -
DllMain()
- 控制台应用程序 -
- 文件存在方式:
- 控制台程序、窗口程序 -
.exe - 动态库:
- linux 下:
.so - windows 下:
DLL
- linux 下:
- 静态库:
- Linux下:
.a - windows下:
.lib
- Linux下:
- 控制台程序、窗口程序 -
编译器
在Linux中使用的编译器是 gcc/g++。
在 Windows 中:
- 编译器 CL.EXE,将源代码编译成目标代码
.obj(二进制)。 - 链接器 LINK.EXE,将多个目标代码、库链接成一个最终文件。
- 资源编译器 RE.EXE,(.rc) 将资源编译,最终通过链接器存入最终文件。
在Linux当中,gcc即能做编译又能做链接。
在Windows当中,编译和链接是两个不同的工具去做,Visual studio 的安装目录下可以搜索到这些编译链接工具。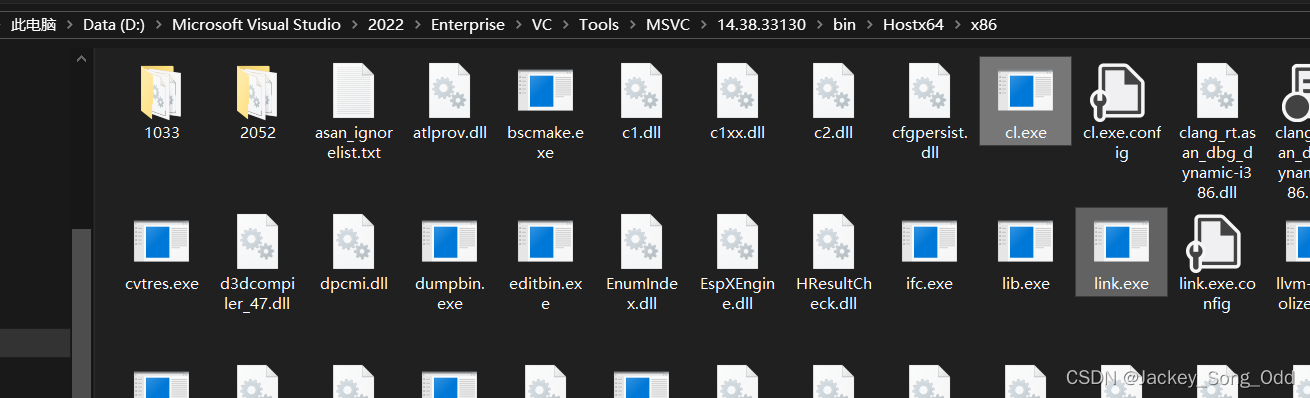
当我们写好代码点击运行的时候:
这个集成的开发环境Visual Studio 会自动调用编译链接工具进行编译。为了清楚编译的细节,有兴趣的话,可以自己在命令行敲入命令自己手动编译一下。
Windows库
- kernel32.dll - 提供了核心的API,例如进程、线程、内存管理等。
- user32.dll - 提供了窗口、消息等API。
- gdi32.dll - 绘图相关的API。
文件目录一般情况下在 C 盘的 /Windows/System32 下:
Windows头文件
- windows.h - 所有windows头文件的集合。
- windef.h - windows 数据类型。
- winbase.h - kernel32的API。
- wingdi.h - gdi32的API.
- winuser.h - user32的API.
- winnt.h - UNICODE字符集支持.
字符编码
编码历史背景
在上个世纪初,由美国人发明计算机的时候,就已经提出了ASC码的编码方式,这种编码方式现在已经被提出来的不多了,在很多大学教材中都不带提的。这种编码方式的特点就是7位二进制代表一个字符,也就是只有2的7次方128个字符,在计算机早期被发明出来的时候,计算机中的内存都非常有限,所以能省一位是一位,不像现在是8位一个字节。128个字符对于美国人来说已经足够用了,26个英文字母大小写加上一些特殊符号和特殊含义的字符。
后来计算机干到了欧洲,为了在欧洲推广销售计算机,老美又提出了ASCII编码方式,也是大多数C语言教材中都会提到的编码方式。8位也就是一个字节代表一个字符,最多可以表示2的8次方也就是256个字符。欧洲绝大多数国家的文字也是像英文那样通过字母的排列来表示不同的意思,所以对于欧洲不同的国家,针对性地进行编码,将字符编码”本地化“。
后来计算机干到了亚洲,那就不得了了,光是汉字就好几万个,一个字节将难以表示所有的汉字,更别说有很多国家了。所以这时候又提出了一种编码方式,叫DBCS(Double Bytes Character Set 双字节字符集)编码方式,这个编码方式主要针对中国、韩国、日本。这种编码方式有个特点就是单双字节混合编码方式,即对于英文仍然使用单字节编码,对于其他字符使用双字节编码。这种编码有很大的缺陷,那就是当文本中既有英文又有汉字,解码时是两两字节解码还是一个一个字节解码,如果解码时弄错了一个字符所占字节的个数,那么就会出现乱码的情况。
再后来就是现在广为人知的UNICODE编码,其中又有很多不同的格式,包括utf-8、utf-16、utf-32。UNICODE编码又称万国码,因为它几乎把世界上所有语言的都收录其中了,大概有十几万个,后续也在进行补充。大多数情况下,在Windows中提到的UNICODE编码多是utf-16编码,在Linux操作系统中提到的编码多是utf-8。utf-16编码的特点是所有的字符不管英文汉字都是占两个字节,英文不够两个字节那就在高位上补0,这样就不存在解析的问题了,也就不会出现乱码的问题。
宽字节数据类型
在Windows编程中,有一个 wchar_t 的类型,每个字符占两个字节,也就是宽字节字符。对比C语言中的 char 一个字符占一个字节。 wchar_t 实际上就是 unsigned short 类型,只不过使用了 typedef 定义了别名。在使用时,需要在字符串的前面加上一个大写的L,告诉编译器按照双字节编译字符串,采用UNICODE编码。
wchar_t* text = L"Hello world!";
wprintf(L"%s\n", text);
在项目属性中可以更改字符集,如果代码中的字符串飘红报错,大概是这里没设置好的问题: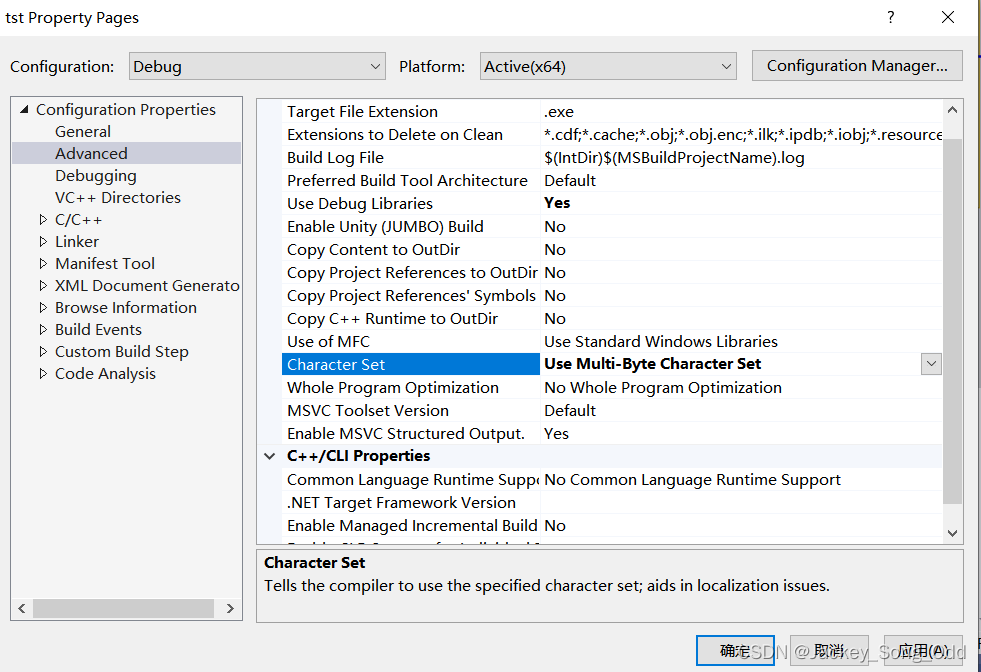
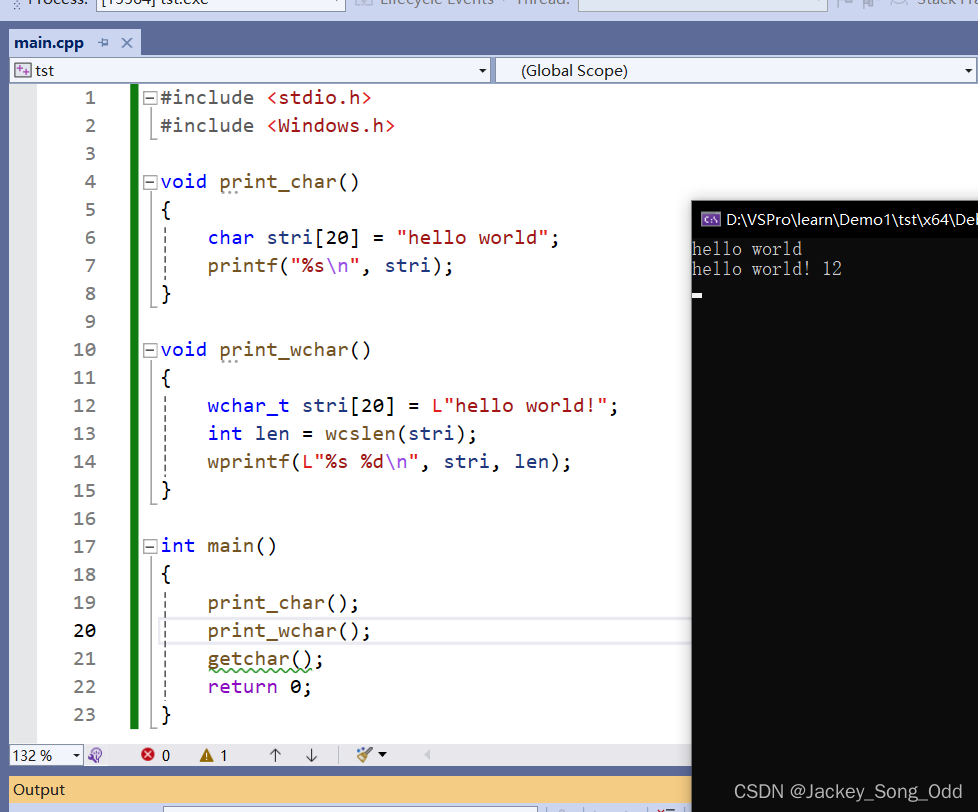
wcslen() 函数求的是字符串的长度,而不是字符串占多少个字节。
TCHAR数据类型
TCHAR 数据类型有的时候是 char,有的时候是 wchar_t。在头文件 winnt.h 中提供了对 UNICODE 的支持,其中有着下面这样一段代码:
1 |
|
__TEXT(quote)也是一个宏, ##双井号拼接quote里面的内容,即加上一个大写的L。
如果分不清 char 和 wchar_t 的时候就可以用 TCHAR 来处理。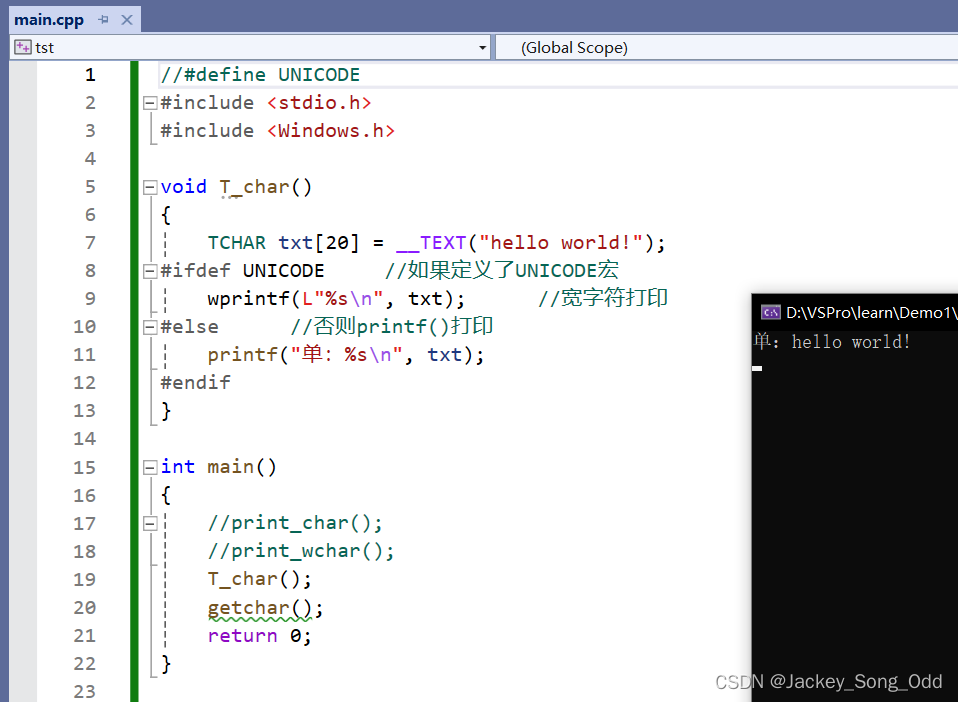
定义 UNICODE 宏时,必须定义在最上面,因为 Windows.h 头文件包含了 winnt.h 头文件,而 winnt.h 头文件中有 #ifdef UNICODE 的判断,只有定义在最上面,才能判断到 UNICODE 宏,这是因为编译器在编译的时候就是从头文件中复制代码进来的,按照代码的上下文关系,UNICODE 宏定义在上面才符合代码的上下逻辑关系,因此才能起到作用。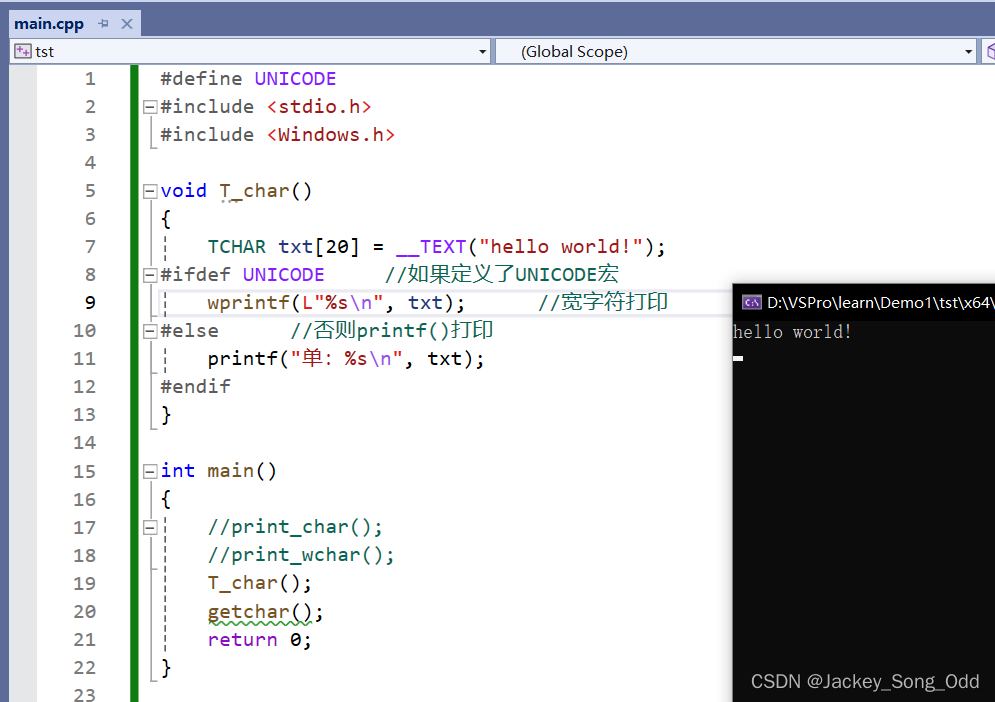
UNICODE 字符打印
wprintf() 函数对汉字的打印并不完善,有很多汉字没法打印。
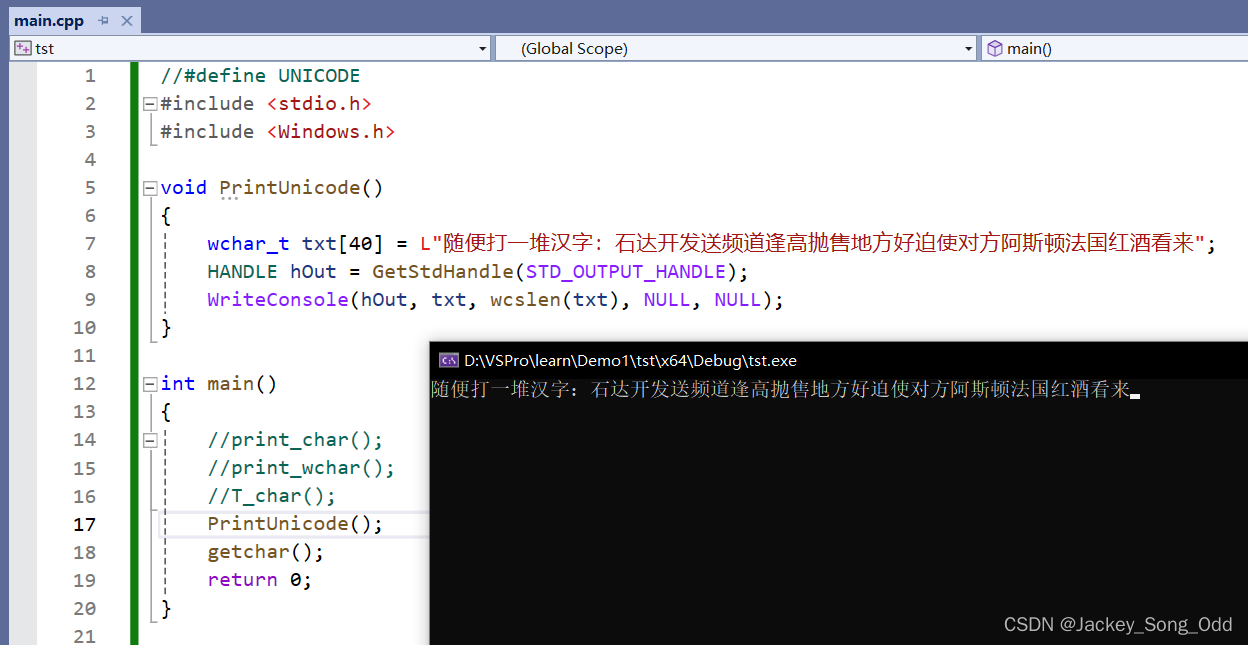
在Windows下使用 WriteConsole API 打印 UNICODE 字符。
HANDLE hOut = GetStdHandle(STD_OUTPUT_HANDLE);
WriteConsole(hOut, 字符串, wcslen(字符串), NULL, NULL);
项目属性改成 Unicode 字符集:(这时编译器在编译的时候会自动在代码前面加一个 #define UNICODE 宏定义)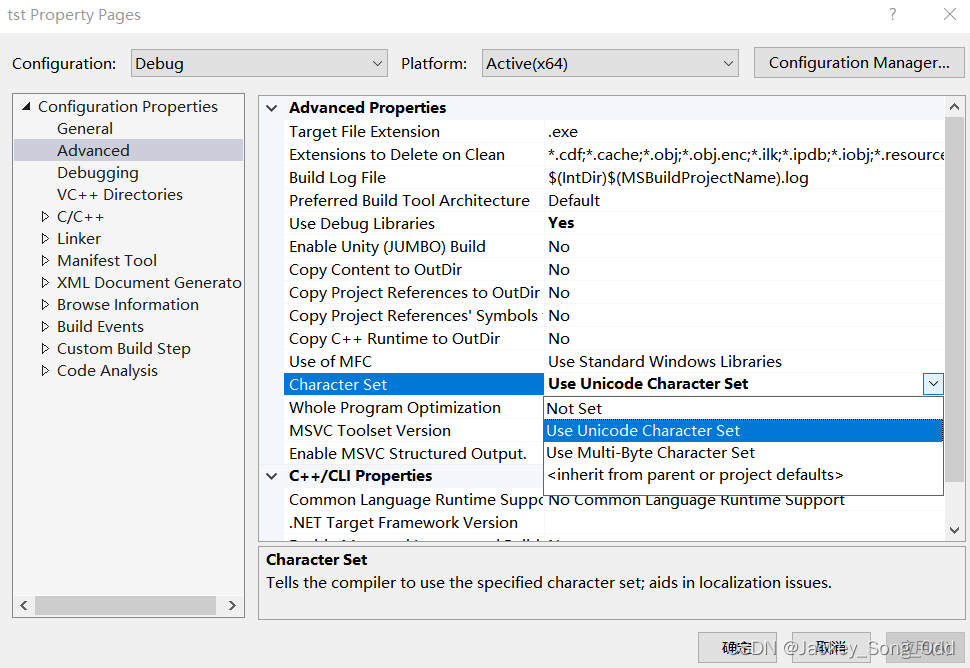
将项目属性设置为多字节字符集的好处
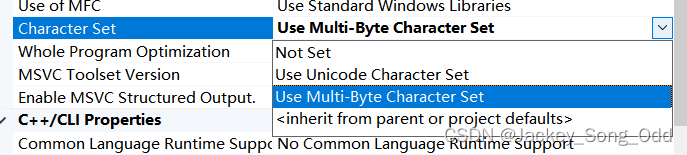
使用 Multi-Byte charater set 目的是为了不让编译器在编译时自动添加 UNICODE 宏定义,这样在写代码时就不用频繁在字符串前面添加大写 L。
微软中使用了很多的别名:
LPSTR等同于char*LPCSTR=const char*LPWSTR=wchar_t*LPCWSTR=const wchar_t*LPTSTR=TCHAR*LPCTSTR=const TCHAR*
微软中很多系统函数调用的参数都是这些别名,尤其是大量使用了 LPTSTR 和 LPCTSTR 这两种类型的情况下,编译时自动添加 UNICODE 宏定义,我们的代码中,字符串前面将不得不加上一个大写 L,这样很麻烦,而使用 Multi-Byte charater set 字符集,将不会自动添加 UNICODE 宏定义,也就意味着不需要频繁地在字符串前面加上大写 L,这样将会省去很多麻烦。



